Olery was founded almost 5 years ago. What started out as a single product (Olery Reputation) developed by a Ruby development agency grew into a set of different products and many different applications as the years passed. Today we have not only Reputation as a product but also Olery Feedback, the Hotel Review Data API, widgets that can be embedded on a website and more products/services in the near future.
We’ve also grown considerably when it comes to the amount of applications. Today we deploy over 25 different applications (all Ruby), some of these are web applications (Rails or Sinatra) but most are background processing applications.
While we can be extremely proud of what we have achieved so far there was always something lurking in the dark: our primary database. From the start of Olery we’ve had a database setup that involved MySQL for crucial data (users, contracts, etc) and MongoDB for storing reviews and similar data (essentially the data we can easily retrieve in case of data loss). While this setup served us well initially we began experiencing various problems as we grew, in particular with MongoDB. Some of these problems were due to the way applications interacted with the database, some were due to the database itself.
For example, at some point in time we had to remove about a million documents from MongoDB and then re-insert them later on. The result of this process was that the database went in a near total lockdown for several hours, resulting in degraded performance. It wasn’t until we performed a database repair (using MongoDB’s repairDatabase command). This repair itself also took hours to complete due to the size of the database.
In another instance we noticed degraded performance of our applications and managed to trace it to our MongoDB cluster. However, upon further inspection we were unable to find the actual cause of the problem. No matter what metrics we installed, tools we used or commands we ran we couldn’t find the cause. It wasn’t until we replaced the primaries of the cluster that performance returned back to normal.
These are just two examples, we’ve had numerous cases like this over time. The core problem here wasn’t just that our database was acting up, but also that whenever we’d look into it there was absolutely no indication as to what was causing the problem.
The Problem Of Schemaless
Another core problem we’ve faced is one of the fundamental features of MongoDB (or any other schemaless storage engine): the lack of a schema. The lack of a schema may sound interesting, and in some cases it can certainly have its benefits. However, for many the usage of a schemaless storage engine leads to the problem of implicit schemas. These schemas aren’t defined by your storage engine but instead are defined based on application behaviour and expectations.
For example, you might have a pages collection where your application expects
a title field with a type of string. Here the schema is very much present,
although not explicitly defined. This is problematic if the data’s structure
changes over time, especially if old data is not migrated to the new structure
(something that is quite problematic in schemaless storage engines). For
example, say you have the following Ruby code:
#!ruby
post_slug = post.title.downcase.gsub(/\W+/, '-')
This will work for every document that has a title field that returns a
String. This will break for documents that use a different field name
(e.g. post_title) or simply don’t have a title-like field. To handle such a
case you’d need to adjust the code as following:
#!ruby
if post.title
post_slug = post.title.downcase.gsub(/\W+/, '-')
else
# ...
end
Another way of handling this is defining a schema in your models. For example, Mongoid, a popular MongoDB ODM for Ruby, lets you do just that. However, when defining a schema using such tools one should wonder why they aren’t defining the schema in the database itself. Doing so would solve another problem: re-usability. If you only have a single application then defining a schema in the code is not really a big deal. However, when you have dozens of applications this quickly becomes one big mess.
Schemaless storage engines promise to make your life easier by removing the need to worry about a schema. In reality these systems simply make it your own responsibility to ensure data consistency. In certain cases this might work out, but I’m willing to bet that for most this will only backfire.
Requirements Of A Good Database
This brings me to the requirements of a good database, more specifically the requirements Olery has. When it comes to a system, especially a database, we value the following:
- Consistency.
- Visibility of data and the behaviour of the system.
- Correctness and explicitness.
- Scalability.
Consistency is important as it helps setting clear expectations of a system. If data is always stored in a certain way then systems using this data become much simpler. If a certain field is required on database level an application doesn’t need to check for the existence of such a field. A database should also be able to guarantee the completion of certain operations, even under high pressure. There’s nothing more frustrating than inserting data only for it not to appear until after a few minutes.
Visibility applies to two things: the system itself and how easy it is to get data out of it. If a system misbehaves it should be easy to debug. In turn, if a user wants to query data this should be easy too.
Correctness means that a system behaves as expected. If a certain field is defined as an numeric value one shouldn’t be able to insert text into the field. MySQL is notoriously bad at this as it lets you do exactly that and as a result you can end up with bogus data.
Scalability applies to not only performance, but also the financial aspect and how well a system can deal with changing requirements over time. A system might perform extremely well, but not at the cost of large quantities of money or by slowing down the development cycle of systems depending on it.
Moving Away From MongoDB
With the above values in mind we set out to find a replacement for MongoDB. The values noted above are often a core set of features of traditional RDBMS’ and so we set our eyes on two candidates: MySQL and PostgreSQL.
MySQL was the first candidate as we were already using it for some small chunks
of critical data. MySQL however is not without its problems. For example, when
defining a field as int(11) you can just happily insert textual data and MySQL
will try to convert it. Some examples:
mysql> create table example ( `number` int(11) not null );
Query OK, 0 rows affected (0.08 sec)
mysql> insert into example (number) values (10);
Query OK, 1 row affected (0.08 sec)
mysql> insert into example (number) values ('wat');
Query OK, 1 row affected, 1 warning (0.10 sec)
mysql> insert into example (number) values ('what is this 10 nonsense');
Query OK, 1 row affected, 1 warning (0.14 sec)
mysql> insert into example (number) values ('10 a');
Query OK, 1 row affected, 1 warning (0.09 sec)
mysql> select * from example;
+--------+
| number |
+--------+
| 10 |
| 0 |
| 0 |
| 10 |
+--------+
4 rows in set (0.00 sec)
It’s worth noting that MySQL will emit a warning in these cases. However, since warnings are just warnings they are often (if not almost always) ignored.
Another problem with MySQL is that any table modification (e.g. adding a column) will result in the table being locked for both reading and writing. This means that any operation using such a table will have to wait until the modification has completed. For tables with lots of data this could take hours to complete, possibly leading to application downtime. This has lead companies such as SoundCloud to develop tools such as lhm to deal with this.
With the above in mind we started looking into PostgreSQL. PostgreSQL does a lot of things well that MySQL doesn’t. For example, you can’t insert textual data into a numeric field:
olery_development=# create table example ( number int not null );
CREATE TABLE
olery_development=# insert into example (number) values (10);
INSERT 0 1
olery_development=# insert into example (number) values ('wat');
ERROR: invalid input syntax for integer: "wat"
LINE 1: insert into example (number) values ('wat');
^
olery_development=# insert into example (number) values ('what is this 10 nonsense');
ERROR: invalid input syntax for integer: "what is this 10 nonsense"
LINE 1: insert into example (number) values ('what is this 10 nonsen...
^
olery_development=# insert into example (number) values ('10 a');
ERROR: invalid input syntax for integer: "10 a"
LINE 1: insert into example (number) values ('10 a');
PostgreSQL also has the capability of altering tables in various ways without
requiring to lock it for every operation. For example, adding a column that does
not have a default value and can be set to NULL can be done quickly without
locking the entire table.
There are also various other interesting features available in PostgreSQL such as: trigram based indexing and searching, full-text search, support for querying JSON, support for querying/storing key-value pairs, pub/sub support and more.
Most important of all PostgreSQL strikes a balance between performance, reliability, correctness and consistency.
Moving To PostgreSQL
In the end we decided to settle with PostgreSQL for providing a balance between the various subjects we care about. The process of migrating an entire platform from MongoDB to a vastly different database is no easy task. To ease the transition process we broke this process up in roughly 3 steps:
- Set up a PostgreSQL database and migrate a small subset of the data.
- Update all applications that rely on MongoDB to use PostgreSQL instead, along with whatever refactoring is required to support this.
- Migrate production data to the new database and deploy the new platform.
Migrating a Subset
Before we would even consider migrating all our data we needed to run tests using a small subset of the final data. There’s no point in migrating if you know that even a small chunk of data is going to give you lots of trouble.
While there are existing tools that can handle this we also had to transform some data (e.g. fields being renamed, types being different, etc) and as such had to write our own tools for this. These tools were mostly one-off Ruby scripts that each performed specific tasks such as moving over reviews, cleaning up encodings, correcting primary key sequences and so on.
The initial testing phase didn’t reveal any problems that might block the migration process, although there were some problems with some parts of our data. For example, certain user submitted content wasn’t always encoded correctly and as a result couldn’t be imported without being cleaned up first. Another interesting change that was required was changing the language names of reviews from their full names (“dutch”, “english”, etc) to language codes as our new sentiment analysis stack uses language codes instead of full names.
Updating Applications
By far most time was spent in updating applications, especially those that relied heavily on MongoDB’s aggregation framework. Throw in a few legacy Rails applications with low test coverage and you have yourself a few weeks worth of work. The process of updating these applications was basically as following:
- Replace MongoDB driver/model setup code with PostgreSQL related code
- Run tests
- Fix a few tests
- Run tests again, rinse and repeat until all tests pass
For non Rails applications we settled on using Sequel while we stuck with ActiveRecord for our Rails applications (at least for now). Sequel is a wonderful database toolkit, supporting most (if not all) PostgreSQL specific features that we might want to use. Its query building DSL is also much more powerful compared to ActiveRecord, although it can be a bit verbose at times.
As an example, say you want to calculate how many users use a certain locale along with the percentage of every locale (relative to the entire set). In plain SQL such a query could look like the following:
#!sql
SELECT locale,
count(*) AS amount,
(count(*) / sum(count(*)) OVER ()) * 100.0 AS percentage
FROM users
GROUP BY locale
ORDER BY percentage DESC;
In our case this would produce the following output (when using the PostgreSQL commandline interface):
locale | amount | percentage
--------+--------+--------------------------
en | 2779 | 85.193133047210300429000
nl | 386 | 11.833231146535867566000
it | 40 | 1.226241569589209074000
de | 25 | 0.766400980993255671000
ru | 17 | 0.521152667075413857000
| 7 | 0.214592274678111588000
fr | 4 | 0.122624156958920907000
ja | 1 | 0.030656039239730227000
ar-AE | 1 | 0.030656039239730227000
eng | 1 | 0.030656039239730227000
zh-CN | 1 | 0.030656039239730227000
(11 rows)
Sequel allows you to write the above query using plain Ruby without the need of string fragments (as ActiveRecord often requires):
#!ruby
star = Sequel.lit('*')
User.select(:locale)
.select_append { count(star).as(:amount) }
.select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) }
.group(:locale)
.order(Sequel.desc(:percentage))
If you don’t like using Sequel.lit('*') you can also use the following syntax:
#!ruby
User.select(:locale)
.select_append { count(users.*).as(:amount) }
.select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) }
.group(:locale)
.order(Sequel.desc(:percentage))
While perhaps a bit more verbose both of these queries make it easier to re-use parts of them, without having to resort to string concatenation.
In the future we might also move our Rails applications over to Sequel, but considering Rails is so tightly coupled to ActiveRecord we’re not entirely sure yet if this is worth the time and effort.
Migrating Production Data
Which finally brings us to the process of migrating the production data. There are basically two ways of doing this:
- Shut down the entire platform and bring it back online once all data has been migrated.
- Migrate data while keeping things running.
Option 1 has one obvious downside: downtime. Option 2 on the other hand doesn’t require downtime but can be quite difficult to deal with. For example, in this setup you’d have to take into account any data being added while you’re migrating data as otherwise you’d lose data.
Luckily Olery has a rather unique setup in that most write operations to our database only happen at fairly regular intervals. The data that does change more often (e.g. user and contract information) is a rather small amount of data meaning it costs far less time to migrate compared to our review data.
The basic flow of this part was:
- Migrate critical data such as users, contracts, basically all the data that we can not afford to lose in any way.
- Migrate less critical data (data that we can re-scrape, re-calculate, etc).
- Test if everything is up and running on a set of separate servers.
- Switch the production environment to these new servers.
- Re-migrate the data of step 1, ensuring data that was created in the mean time is not lost.
Step 2 took the longest by far, roughly 24 hours. On the other hand, migrating the data mentioned in steps 1 and 5 only took about 45 minutes.
Conclusion
It’s now been almost a month ago since we completed our migration and we are extremely satisfied so far. The impact so far has been nothing but positive and in various cases even resulted in drastically increased performance of our applications. For example, our Hotel Review Data API (running on Sinatra) ended up having even lower response timings than before thanks to the migration:
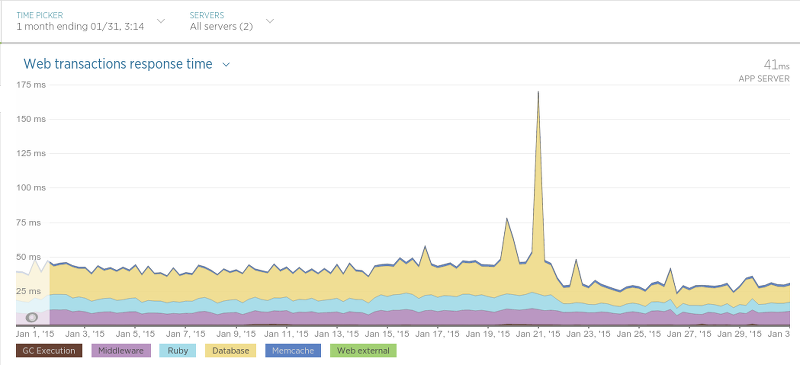
The migration took place on the 21st of January, the big peak is simply the application performing a hard restart (leading to slightly slower response timings during the process). After the 21st the average response time was nearly cut in half.
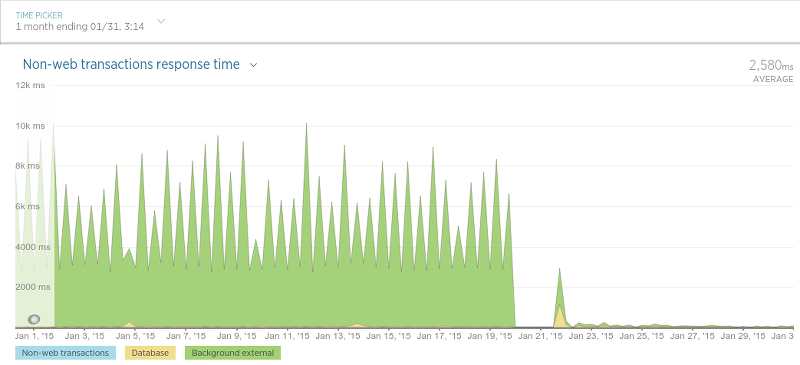
Another case where we saw a big increase in performance was what we call the “review persister”. This application (running as a daemon) has a rather simple purpose: to save review data (reviews, review ratings, etc). While we ended up making some pretty big changes to this application for the migration the result was very rewarding:
Our scrapers also ended up being a bit faster:
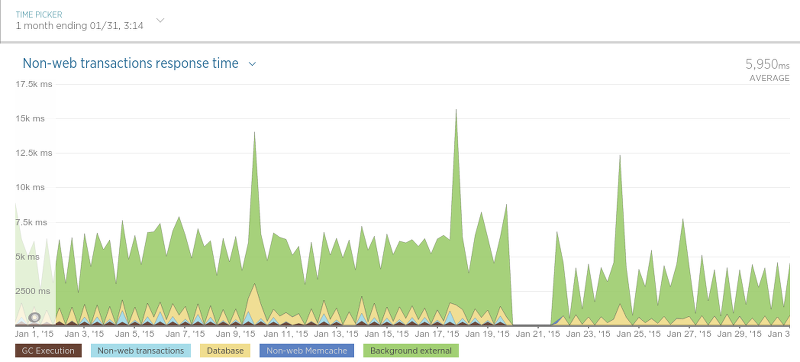
The difference isn’t as extreme as with the review persister, but since the scrapers only use a database to check if a review exists (a relatively fast operation) this isn’t very surprising.
And last the application that schedules the scraping process (simply called the “scheduler”):
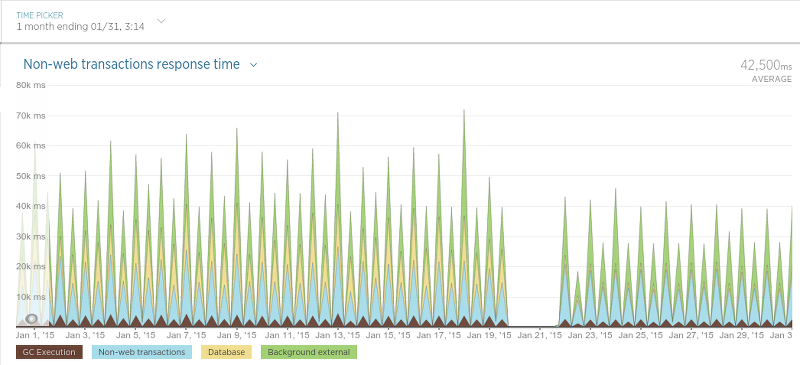
Since the scheduler only runs at certain intervals the graph is a little bit hard to understand, but nevertheless there’s a clear drop in the average processing time after the migration.
In the end we’re very satisfied with the results so far and we certainly won’t miss MongoDB. The performance is great, the tooling surrounding it pales other databases in comparison and querying data is much more pleasant compared to MongoDB (especially for non developers). While we do have one service (Olery Feedback) still using MongoDB (albeit a separate, rather small cluster) we intend to also migrate this to PostgreSQL in the future.